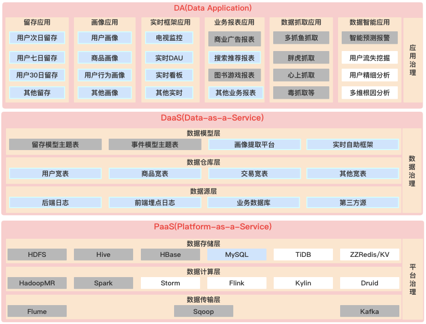
数据中台常见技术架构
gio 的技术架构
1. 数据采集传输
1.1 数据采集工具
| 名称 | 开发公司 | 场景 | 简述 | 优劣性 |
|---|---|---|---|---|
| Flume | Cloudera | 实时采集日志引擎 | 分布式海量日志采集 | |
Flume 简介
Flume是一种提供高可用、高可靠、分布式海量日志采集、聚合和传输的系统。它支持在日志系统中定制各类数据进行发送,用于采集数据;同时,它支持对数据进行简单处理,并写到各种数据接收方。
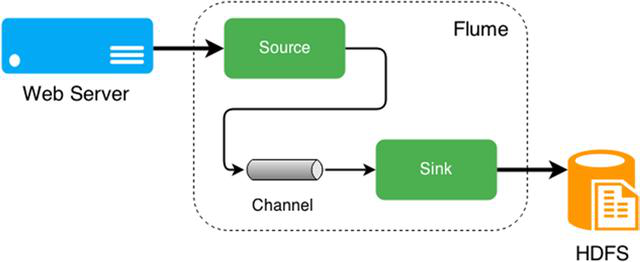
数据源种类有很多,可以来自directory、http、kafka等,Flume提供了Source组件用来采集数据源。Source种类如下:
(1)spooling directory source:采集目录中的日志
(2)htttp source:采集http中的日志
(3)kafka source:采集kafka中的日志
采集到的日志需要进行缓存,Flume提供了Channel组件用来缓存数据。Channel种类如下:
(1)memory channel:缓存到内存中(最常用)
(2)JDBC channel:通过JDBC缓存到关系型数据库中
(3)kafka channel:缓存到kafka中
缓存的数据最终需要进行保存,Flume提供了Sink组件用来保存数据。Sink种类如下:
(1)HDFS sink:保存到HDFS中
(2)HBase sink:保存到HBase中
(3)Hive sink:保存到Hive中
(4)kafka sink:保存到kafka中
使用场景有:
- 日志--->Flume--->实时计算(如kafka/MQ+Storm/Spark Streaming)
- 日志--->Flume--->离线计算(如ODPS、HDFS、HBase)
- 日志--->Flume--->ElasticSearch等
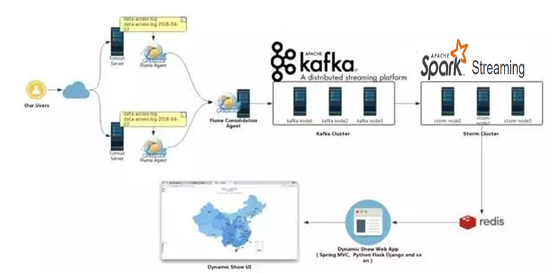
下面结合一个大数据实时处理系统(Flume+Kafka+Spark Streaming+Redis)阐述下Flume在实际应用中所扮演的重要角色。该实时处理系统整体架构如下:通过部署在web 服务器上的agent 将数据传动到
2. 数据存储计算
3. 数据可视化
4. 数据挖掘
参考文章: